


Table of Contents
Imagine a world where data is as abundant as air, yet every piece is crafted with precision, free from privacy concerns. Welcome to the realm of synthetic data—an innovative solution that’s revolutionizing how businesses handle information.
What is Synthetic Data?
At its core, synthetic data is artificially generated data designed to mimic real-world data. It’s created using sophisticated algorithms and statistical models, ensuring it closely resembles actual data without containing any unique identifiers. This means you get all the benefits of real data without the risks of privacy breaches.
Why Synthetic Data is a Game-Changer
- Privacy Protection: One of the most significant advantages of synthetic data is its ability to protect privacy. By generating data that mirrors real-world patterns without exposing personal information, companies can conduct research and development without the risk of compromising individual privacy.
- Cost-Effectiveness: Gathering real data can be an expensive and time-consuming process. Synthetic data, on the other hand, can be produced quickly and at a lower cost. This makes it an attractive option for startups and businesses looking to optimize their budgets.
- Versatility: Synthetic data isn’t just a one-trick pony. It has a wide range of applications, from machine learning and product testing to market research. Its versatility makes it a valuable asset across various industries.
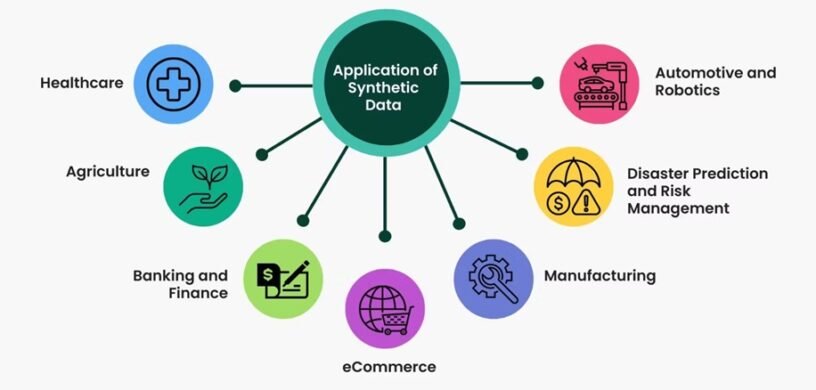
Real-Life Examples of Synthetic Data in Action
- Machine Learning: Imagine a tech company developing an AI model to detect fraudulent transactions. Using real transaction data might expose sensitive customer information. Instead, the company uses synthetic data that replicates the patterns of real transactions. This allows the AI to learn effectively without any privacy concerns.
- Product Testing: Consider a car manufacturer testing new autonomous driving technology. Collecting real-world driving data can be challenging and costly. Synthetic data can simulate countless driving scenarios, from city traffic to highway conditions, providing the necessary data for testing and improving the technology.
- Market Research: A retail company wants to analyze shopping behavior to optimize its marketing strategies. Instead of conducting extensive and expensive surveys, they generate synthetic data reflecting various shopping patterns. This enables them to gain valuable insights quickly and cost-effectively.
The Future is Synthetic: Gartner’s Bold Prediction
The potential of synthetic data is immense, and its adoption is rapidly increasing. According to Gartner, by 2026, 75% of businesses will be using generative AI to create synthetic data. This forecast underscores the growing recognition of synthetic data’s value in driving innovation while safeguarding privacy.
Conclusion
Synthetic data is more than just a technological advancement; it’s a paradigm shift in how we handle and utilize information. By offering a cost-effective, privacy-protecting alternative to real data, it opens up new avenues for innovation across various industries. As businesses increasingly adopt synthetic data, we’re poised to see significant advancements in AI, product development, and market strategies.
So, whether you’re a startup looking to innovate or an established company seeking to optimize, synthetic data could be your key to unlocking a future of limitless possibilities. Embrace the synthetic revolution and stay ahead in the data-driven world.

Frequently Asked Questions About Synthetic Data
What is synthetic data with an example?
Synthetic data is artificially generated to mimic real-world data. For example, a financial institution might generate synthetic transaction data to train an AI model for fraud detection without risking customer privacy.
Why is synthetic data important?
Synthetic data is crucial because it protects privacy, reduces costs, and provides versatile applications across various industries, enabling innovation and development without the constraints of real data.
What is the difference between synthetic and artificial data?
While both terms are often used interchangeably, synthetic data specifically refers to data generated to mimic real-world data patterns, whereas artificial data can include any data created through non-natural means, not necessarily mimicking real data.
What is synthetic data for pharma?
In the pharmaceutical industry, synthetic data can simulate patient records and clinical trial data, allowing researchers to conduct studies and develop treatments without exposing sensitive patient information.
How is synthetic data used in machine learning?
Synthetic data is used in machine learning to train models, particularly when real data is scarce, sensitive, or expensive to obtain. It provides diverse and extensive datasets for robust model training.
Can you provide some synthetic data examples?
Examples include synthetic financial transaction data for fraud detection, synthetic patient data for healthcare research, and synthetic driving scenarios for testing autonomous vehicles.
What is synthetic data AI?
Synthetic data AI involves using artificial intelligence to generate synthetic data. AI algorithms create realistic, diverse datasets that mirror the patterns and distributions of real-world data.
What is synthetic data LLM?
In the context of Large Language Models (LLMs), synthetic data can be used to train these models, providing vast amounts of text data that resemble real-world language usage without compromising privacy.
How is synthetic data used in healthcare?
In healthcare, synthetic data is used to simulate patient data for research, training, and testing purposes. It helps in developing new treatments, improving patient outcomes, and safeguarding patient privacy.
What is the difference between synthetic and simulated data?
Synthetic data is created to mirror real-world data patterns, while simulated data is generated to replicate specific scenarios or processes, often for testing or training purposes.
Leave a Reply